シミュレーション環境とテストベンチ構成

設計仕様書を作成し、HDL(Verilog-HDL)で論理回路を記述した後にするのが、論理シミュレーションでのデバッグです。
私の場合のシミュレーション環境とテストベンチ構成をお知らせします。
参考にしていただければと思います。
考え方
私の場合のシミュレーション環境とテストベンチ内の構成の考え方についてご説明します。
基本的には、RTLシミュレーションから実遅延検証まで流用できるような構成で記述しています。
テストベンチのTOPは、1つのファイル。
テストベンチのTOP内でテストシナリオファイル*1をインクルードする構成にしています。
また、テストシナリオファイルはシミュレーション前に各テストシナリオファイルから1つをコピーしてテストシナリオファイルを作り、シミュレーションを開始します。
下の図がファイル構成のイメージです。
例えば)
シミュレーション開始前に「Scenario02.v」を「TestScenario.v」にコピーします。
※これは手動で行っても良いし、スクリプトファイルを作り、コマンドラインで番号(01とか02など)を指定することで自動的にコピーするようにしても構いません。
そして、「TestBench.v」をコンパイルすることで、
「TestScenario.v」がインクルードされます。

このような構成にする理由ですが、
テストベンチのTOPは、ターゲット回路だけでなく、クロック生成、リセット生成、対向モデルなど、色々と配置します。
もし、テストシナリオ毎にターゲット回路を配置し、対向モデルの配置、クロックの生成など記述していたら、端子が変更になったりした場合に修正するファイルが増えるからです。
簡単な機能のLSIならいいですが、通信系や画像処理など、100シナリオ、1000シナリオになる場合は、大変な作業です。
なので、シミュレーション環境を構築する場合も、モジュールの切り分けと同様に、共通して使えるものはテストベンチTOPで記述し、シナリオ毎に変更するものはテストシナリオで記述するように、検証開始前の検証プラン時に検討する必要があります。
テストベンチTOP
テストベンチのTOP(TestBench.v)に何を記述(配置)するのか。。。
私の場合、ある程度基本構成ができています。
- ターゲット回路に必要な信号の宣言と入力信号の初期値記述
- クロックや入力遅延などのパラメータ宣言
- テストシナリオのインクルード
- クロックの生成
- ターゲット回路の配置(インスタンス)
- テストシナリオで共通で使用できるTaskやFunction記述
- 対向モデルの配置(インスタンス)
記述で重要となるのが、テストシナリオをどこでインクルードするか。
です。
コンパイラは、記述の上から順に解析していきます。
従って、
テストシナリオファイルで必要となる信号は、インクルードする前に宣言と初期値を設定しておきます。
尚、TaskやFunctionは、記述の順番には関係ないので、インクルード後に記述しても問題はないです。
では、簡単ですが、TestBench.v記述例を下に示します。
説明は、記述例の下に記載しています。
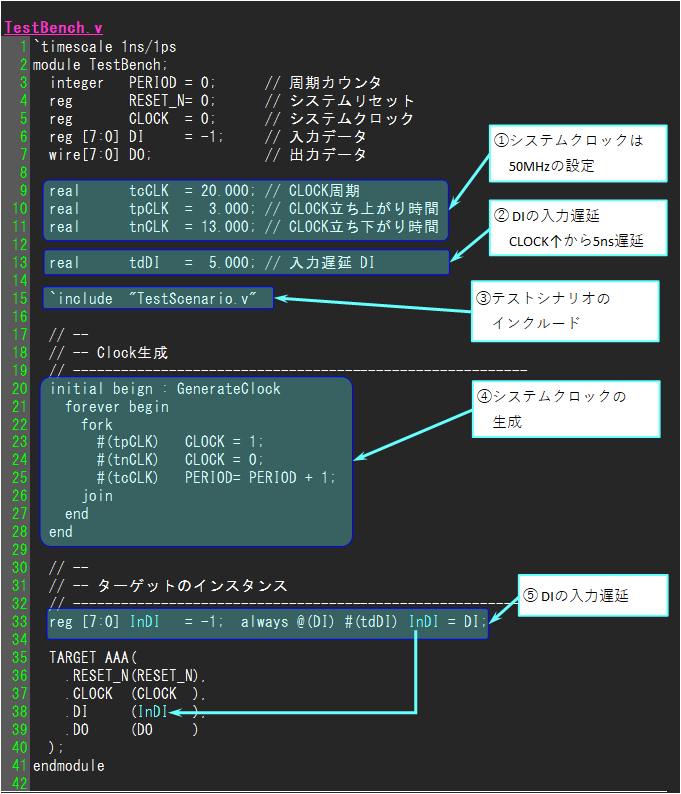
テストベンチ記述例の説明
1行目
シミュレーションのタイムスケールを記述します。
ここでは、1ns/1psです。
#での時間の整数部が1ns単位、小数部が1psと示しているだけです。
3~7行目
信号の宣言と初期値を同時に設定した書き方になっています。
尚、ターゲット回路の入力信号は、reg宣言で初期値を設定できるようにしておき、出力信号はwire宣言します。
9~11行目
テストシナリオ毎でクロックの周波数を変更できるように記述しています。
※テストシナリオで変更しない限り、この記述した時間でクロックが生成されます。
(50MHzで良ければ、テストシナリオ内で記述しなければよいだけです)
なぜreal宣言としているかというと、parameter宣言だとテストシナリオ内で変更できない為です。
尚、小数を含まない場合は、integerで良いです。
13行目
ターゲット回路へ入力する信号の入力遅延です。
(クロック及びリセットを除いた入力信号です)
これは、実遅延検証を意図した時の入力遅延になります。
この値も、このままで良ければ、テストシナリオ内で記述しなければよいだけです。
このようにしている理由は、クロックの周波数と同じ考えです。
15行目
テストシナリオのインクルードです。
20~28行目
クロックの生成となります。
ここは出荷試験用パターンのクロック波形指定が色濃く残っています。
周期の変数を示すPERIODがあり、PERIODの変化を基準にクロックの立ち上がり時間、立ち下がり時間を設定しています。
尚、シミュレーション終了前にPERIODの値を表示することで、パターン数がわかります。
33行目
入力遅延です。
宣言と遅延回路を1行で記述しています。
尚、InDIの初期値は、6行目のDIの初期値と一緒にする必要があります。
遅延なので、assign文で記述したい所ですが、assignで記述するとシミュレーション開始時に不定値から始まります。
テストシナリオ
テストシナリオでは、テストベンチTOPでインクルードされることを意図して記述します。
尚、テストシナリオ内だけ使用する信号は、わざわざテストベンチTOPで宣言する必要は無く、テストシナリオ内で宣言、初期値設定を行っても良いです。
では、簡単ですが、TestScenario.v記述例を下に示します。
説明は、記述例の下に記載しています。

テストシナリオ記述例の説明
10~12行目
システムクロック周期と波形を変更しています。
ここでは、すでにテストベンチで宣言された変数の為、initial文で変更しています。
17行目
入力遅延を変更しています。
ここでは、すでにテストベンチで宣言された変数の為、initial文で変更しています。
23~25行目
パワーオンリセットの動作記述になります。
リセット信号は、PERIODの変化点で変化するようにしています。
もし、PERIODの変化から数ns遅延したい場合は、#で遅延したら良いだけです。
27~29行目
ターゲット回路への入力値を生成しています。
これは、クロックの立ち上がりに同期させて入力させています。
尚、テストベンチであろうと、クロックと同期させる場合は、<=(ノンブロッキング代入)で記述してください。
もし、=(ブロッキング代入)で記述し、入力遅延を0nsとした場合、シミュレーターによっては次のクロックの立ち上がりでラッチせず、同時にラッチすることがあります。
※入力遅延の記述が無くても、同じです。気を付けてください。
繰り返しの場合、for文を使いたいですが、私は変数宣言が面倒なので、repeat文をよく使用します。
シミュレーション
上記TestBench.vとTestScenario.vを使って、シミュレーションするとどのような波形になるのか、以下に示します。

テストシナリオ内で、クロック周波数(波形)と入力遅延が変更されるので、上図のようになります。
尚、テストベンチ内でDI[7:0]及びInDI[7:0]に-1を記述しているので、DI[7:0]では255になります。
これは、8'hFFや255など記述が面倒だった為です。
テストベンチは静的解析ツールを通さないので、固定数にbitを示す記述はしません。
次の製品でbit幅が変わった場合、修正するのが面倒な為です。
尚、-1は32bitとまでとなる為、32bitを超える場合は、{33{1'b1}}と記述したりします。
最後に
Verilogの参考書にはテストベンチの記述について、書かれているものは、無いと思っています。(実務に沿っていない教科書)
上記説明は、私が色々な案件を受け持ち(掛け持ちもありました)、シミュレーション環境を構築する上で、施行錯誤して整ってきた環境と構成になります。
色々な機能のLSIがあるので、これが正解というものはありませんが、上記説明がこれからのシミュレーション環境や構成を検討する上で利用して頂ければと思います。
*1:テストパターンやテストスイートなど言ったりしますが。。。
組み込みソフトでレジスタにアクセス

FPGA内にCPUを配置した場合、CPUからLogic内のレジスタにアクセスする時のC言語記述についてです。

CPUからレジスタにリード/ライトする場合、C言語の予約語「volatile」が重要になります。
volatileは、C言語ソースをコンパイルする時の「最適化を抑止」します。
と、よく書かれていますが、最初はピンとこなかったです。
コンパイラの最適化とは、論理合成みたいなイメージだと思っています。
冗長なものは削除したり、処理の順番を変更したりします。
※極力プログラム量(.text領域)を小さくしようとします。
なので、論理回路エンジニア(HDL記述者)がC言語を使って組み込みソフトの設計をする場合、volatileを意識する必要があります。
レジスタにアクセスする場合以外に、for文を使ってWait関数を作る場合は必要になります。
CPUをNIOSにする場合
レジスタリード/ライト用のマクロが準備されていますので、それを使用します。
レジスタライト:マクロIOWR( ) や IOWR_?
レジスタリード:マクロIORD( )や IORD_?
を、それぞれ使用します。
尚、このマクロを使用する場合、io.hをIncludeする必要があります。
※パスは、bsp/HAL/inc/io.h
どのようなマクロなのかは、io.hをみてください。
このマクロを使用することで、最適化時に別のアドレスになったり、
削除されたりすることはありません。
また、キャッシュもバイパスします。
CPUをMicroBlazeにする場合
volatileを使って、レジスタへのアクセスは可能です。
が、これではキャッシュの制御ができなため、MicroBlazeの場合も
マクロが準備されています。
レジスタライト:Xil_out?
レジスタリード:Xil_in?
尚、このマクロを使用する場合、xil_io.hをincludeする必要があります。
CPUをARMにする場合
volatileを使ってレジスタにアクセスしてください。
volatileやマクロを使わずC言語ソース作った場合、
実機確認した時やCo-Simした時に レジスタへのアクセス無かったり、アクセスの順番が変わっていたりします。
※気付きにくいところなので、注意して記述してください。
余談)
組み込みソフトを速く動作させたい場合は、
① 関数分け細分化させない。
流用性と可読性は悪くなりますが、関数呼び出しのスタックへのアクセスが
少なくなります。
※defineでマクロを作ったり、INLINEを使用する方法もあります。
② 関数への引数や戻り値は、グローバル変数にする。
これも、スタックへのアクセスが少なくなります。
ハードとソフトのトレードオフ

ハードとソフトのトレードオフについて、どう考えますか?
ここでいうハードとはASIC/FPGAのロジック部分、ソフトはARMやNIOSなど組み込みソフトのことをいいます。
私の切り分けは、以下の通りです。
【ソフトウェア】
・ユーザーと通信を行う箇所
例えば、
PC上のユーザインターフェイスで設定された値を解析したり、
不定期で通信を行う部分、通信仕様が今後変更になりそうな部分など。
・リアルタイムで処理が必要ない部分
【ハードウェア】
・外部デバイスと定期的に通信を行う部分
・リアルタイムで処理が必要な部分

上図より、
PC I/Fは、PCとの通信の為、リアルタイムに処理を行います。
PCから受信があれば、受信データをバッファにため、割り込みを発生します。
また、CPUからの送信データを送信します。
CPUは、PCからの受信データを解析し、各種処理のレジスタを設定します。
特にPCで設定した値をレジスタ用に変換したりします。
例えば、
変倍率から変倍カウンタの加算値を求め、固定小数に変換したりなど。。。

※上式は小数部が8bitの場合となり、演算結果の整数部をレジスタに
設定することで、固定小数部8bitを含めた値を設定します。
Camera I/F → 画像処理 → Monitor I/Fは、リアルタイムで処理します。
定期的にCameraに対し入力画像を取得し、各画素に対して処理を行い、
定期的にMonitorに出力します。
画像処理の基本 その3

画像処理の拡大と縮小処理です。(メモリを使用する場合)
基本概念は以下の通りです。
【拡大処理】
入力された画像データをメモリに格納し、変倍カウンタに応じて、
メモリからリードして拡大します。
【縮小処理】
変倍カウンタに応じてメモリに格納し、1ライン格納終了後、
メモリを順にリードします。
処理イメージは、以下の通りです。(拡大は3倍、縮小は1/3倍を例)

※横方向への拡大縮小をイメージ化しています。縦方向も同様の考えになります。
上記イメージは単純拡大と単純縮小をした場合に当ります。
これをそのまま出力するとカクカクした画像になります。
そのカクカクした画像を滑らかにする為に色々な補間処理を行います。
拡大処理の場合は、メモリからリードする時に補間処理を行い、
縮小処理の場合は、メモリにライトする時に補間処理を行います。
尚、補間方法は、
リニア補間、バイリニア補間、バイキュービック補間などがあります。
変倍カウンタとは?
変倍カウンタは、整数部と小数部に分かれたカウンタで、
整数部がメモリのリードアドレスやライトアドレスとなり、
小数部が注目画素からの距離となります。
この小数部は補間処理で利用したりします。
このカウンタは変倍率に応じて加算します。
例えば、
3倍の場合、リードするたびに0.333づつカウントアップし、
1/3倍の場合、整数部と入力画素位置が一致した時に3.000づづカウントアップします。
拡大と縮小時のカウントアップは以下のように動きます。
【拡大時】

【縮小時】

変倍カウンタの設計は固定小数とし、変倍精度に応じて小数部のbit精度を変更します。
また、変倍カウンタの加算値は、ソフトで変倍率から加算値を求め、レジスタ設定する方が効率的です。
画像処理の基本 その2

画像処理で過去のラインを使ってマトリクス演算する場合です。
例えば、
フィルタ処理、JPEGで使うDCTなど
外部デバイス(CCDなど)からライン毎に画像データが入力される場合、
フレームメモリを使用せずラインメモリを使って、必要な過去ラインデータを
取得する時に使用します。
特に、現ライン入力と同時に処理させる場合に使用します。
構成イメージは、以下の通りです。(3x3マトリクスを例)

現ラインと同時にラインメモリに保存した過去のデータをリードしてマトリクス作成します。 (トコロテンみたいなイメージ)
この時のラインメモリをFIFOにするか、RAMにするかは、エンジニアの好みだと思います。
フレーム間で差分を出したり、H.264など、過去のフレームが必要になる場合も
Line MemoryからFrame Memoryに代わるだけです。
(DDR3 SDRAMなど使用する場合、メモリ領域を分割して使用します)